关于散列(Hash), 网上的介绍有很多,这里就不费力介绍.
而对于这个具体的项目要求来说, 我们所做的只是需要把一个图像转换为一个Hash值, 然后储存到字典中. 并且有一下要求:
- 视觉上相差不大的图片, 他们的Hash值也应该相同
- 这个Hash计算需要快, 因为有时候数据量会很大
那么我们有以下几个Hash函数的选择:
- 差分散列(difference hashing)
- md5
- sha-1
最终我们选择了差分散列的方法, 有以下的原因:
- 差分散列速度很快, 计算量小
- 对于肉眼相差不大的图片, 差分散列可以得出相似的值
- md5 和 sha-1 只要有一点变化, 输出值就会完全改变(这本来很好, 但在这里非常不好!)
Detect and remove duplicate images from a dataset for deep learning
文章链接:
https://www.pyimagesearch.com/2017/11/27/image-hashing-opencv-python/
前言:
为什么要删去数据集中重复的图片?
Having duplicate images in your dataset creates a problem for two reasons:
- It introduces bias into your dataset, giving your deep neural network additional opportunities to learn patterns specific to the duplicates
- It hurts the ability of your model to generalize to new images outside of what it was trained on
Take the time to remove duplicates from your image dataset so you don’t accidentally introduce bias or hurt the ability of your model to generalize.
一. 关于图像散列值
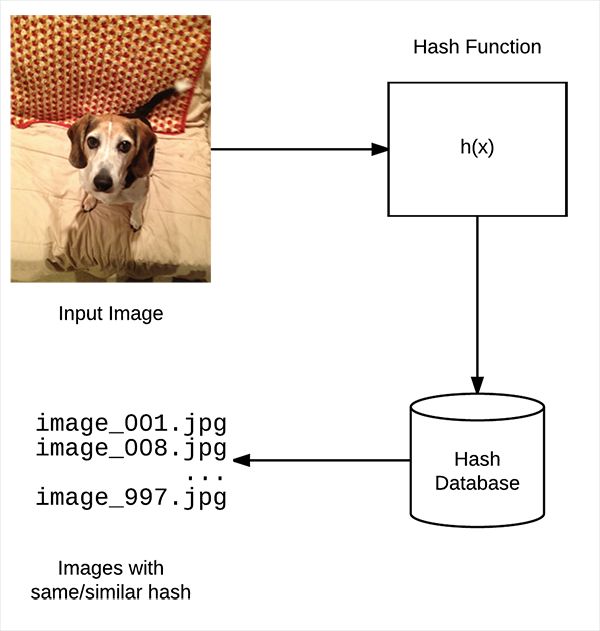
关于散列(Hash), 网上的介绍有很多,这里就不费力介绍.
而对于这个具体的项目要求来说, 我们所做的只是需要把一个图像转换为一个Hash值, 然后储存到字典中. 并且有一下要求:
- 视觉上相差不大的图片, 他们的Hash值也应该相同
- 这个Hash计算需要快, 因为有时候数据量会很大
那么我们有以下几个Hash函数的选择:
- 差分散列(difference hashing)
- md5
- sha-1
最终我们选择了差分散列的方法, 有以下的原因:
- 差分散列速度很快, 计算量小
- 对于肉眼相差不大的图片, 差分散列可以得出相似的值
- md5 和 sha-1 只要有一点变化, 输出值就会完全改变(这本来很好, 但在这里非常不好!)
二. 我们所需的步骤
1. Convert to grayscale 转灰度
在这里, 颜色信息对于判定两张图是否相同其实并不是很重要, 所以将三通道转为一个通道可以很好的减少我们的工作量
2. Resize 忽略长宽比缩放
这是为了得到一个合适的大小, 以便符合后续的Hash计算, 所有需要保证所有的图片具有相同的大小尺寸, 这牵扯到差分散列的工作原理, 这会在后面解释
在这里, 我们需要将原图缩放到只有$ 9 * 8 $大小
3. Compute the difference 计算差分(梯度)
差分散列算法, 故名思与需要计算差分信息, 在图片里, 指的就是相邻像素之间的梯度.
好了, 这就是之前我们为什么需要 $ 9 * 8 $ 像素的原因了
因为我们需要得到的是一个64位的二进制信息, 而 $8 * 8=64$ , 由于是计算差分(梯度), 所以必然需要九行
需要注意: 这里虽然说是差分, 但实际上使用的是非常简化的版本: 但前一个像素大于后一个像素时, 给出一个$1$, 否则, 给出一个$0$, 也就是说, 可以看作只提取梯度的正负符号信息, 公式为
$P[x] > P[x + 1] = 1 else 0$
那么现在我们得到了一个64bit的值, 接下来就对他进行Hash计算
4. Build the hash 计算散列值
def dhash(image, hashSize=8):
# convert the image to grayscale and resize the grayscale image,
# adding a single column (width) so we can compute the horizontal
# gradient
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, (hashSize + 1, hashSize))
# compute the (relative) horizontal gradient between adjacent
# column pixels
diff = resized[:, 1:] > resized[:, :-1]
# convert the difference image to a hash and return it
return sum([2 ** i for (i, v) in enumerate(diff.flatten()) if v])
5. 初始化字典, 寻找重复并输出
略